5π Consulting
$15 Production Kubernetes Cluster on DigitalOcean
November 20, 2016
 Four sweets or production Kubernetes for a month
Four sweets or production Kubernetes for a month
Introduction
As you might already know, I’m into containers, static configuration and self-service infrastructures. Naturally, I love Kubernetes, which I consider the most promising cluster scheduler around.
In fact, the biggest reason to use containers is that they make it possible for something like Kubernetes to operate your cluster. Cluster scheduler like Kubernetes, Mesos or Swarm take care of deploying and moving your applications around without requiring an Operator to allocate resources and redeploy services manually.
Cluster schedulers are here to stay. They will become as ubiquitous as version control and getting experience with it is something I can encourage everyone in the DevOps world to do. Especially if your job is mainly operating. Chances are, your job gets automated.
Getting Kubernetes up somehow is easy. There are tons of scripts for doing that. But those setups are intended as temporary test environments. Setting up a production environment is much harder and unfortunately not very well documented.
Reading this you will realize that there are things you might not want to do this way in production and I agree. So I’m sorry if the title is a bit click-baity. The reason I’m still calling this ‘production’ is because this setup is highly available, TLS authenticated and has a way going forward which doesn’t require you to start from scratch like most Containers/Kubernetes getting started guides.
You can find all code mentioned here: https://github.com/5pi
Overview
 Mainly to keep things cheap, I choose DigitalOcean and use the smallest $5/month instances. For a highly available cluster, we need at least three hosts.
Mainly to keep things cheap, I choose DigitalOcean and use the smallest $5/month instances. For a highly available cluster, we need at least three hosts.
Kubernetes doesn’t schedule containers directly, it schedules Pods which again can consist of multiple containers sharing the same storage volumes and IPs. The pods running on different hosts need to communicate with each other. There are several options to do this, like using overlay networks, routing IP ranges to each server on you routers or co-locating the servers on the same ethernet segment.
Since static routes are least complex to setup and maintain, while allowing to grow easier than with one ethernet segment for all pod IPs, it’s the option I choose here.
Because on DigitalOcean there is no way to have custom routes, I’m using tinc to form a private, flat ethernet segment and route a /24 to each host.
To consider the infrastructure immutable, we need to store state externally. Fortunately DigitalOcean just released their block storage product which we use to store pod volumes on.
We will also create DNS names to make accessing the cluster easier:
- master0X.[domain] points to a hosts internal IP; Used for tinc to connect to peers
- edge0X.[domain] points to a hosts public IP; Used for remote access etc
- edge.[domain] points to edge float IP; Used to reach LB directly
- *.edge.[domain] also points to edge float IP; Used for virtual hosts on LB
Kubernetes Deployment
Configuration
The infra repository contains all sources needed to build the images and deploy the stack. Beside the committed configuration in the repository, there is also some cluster specific configuration required. While some of it only affects the cluster deployment, other is included in the images. This means changing this always requires rebuilding the images. The configuration is kept in config/.
To create a new cluster, first checkout the repo, edit config/env and run ./mk_credentials to create credentials:
$ git clone [email protected]:5pi/infra.git
$ cd infra
$ vi config/env
$ ./mk_credentialsBuilding Images
As described in the README, to build the images run make -C packer after you created the configuration and credentials.
Deploying Stack
Deployment is configured in tf/ and uses terraform. It spins up hosts with the specified image and allows the provided ssh key to connect. It also creates the DNS records required for tinc to connect to peers and external users to access services on the cluster.
Since we didn’t want to include all necessary configuration and credentials in the image for flexibility and security, we need to upload the remaining configuration, like TLS keys, after spinning up the host. To set general configuration, /etc/environment.tf is created and can be sourced by scripts in the image to get deploy-time configuration.
To deploy a new cluster, you first probably want to change tf/id_rsa.pub to include your SSH public key. You need to run ssh-agent and the key needs to be added to it’s keyring with ssh-add. The key may not exist on DigitalOcean already. You can run ssh-keygen -f id_rsa && ssh-add id_rsa in tf/ to create a new keypair.
You also need to create the domain you specified in config/env in DigitalOcean before proceeding. For whatever reason DO requires you to attach the records to some droplet. It doesn’t really matter which one.
To spin up the configured cluster with the built image, run:
./terraform apply -var cluster_state=new -var 'image="image-id-from-last-step"'
Be careful to quote the image parameter properly like described here). cluster_state is required to make etcd not wait for consensus before spinning up the next instance.
That’s it! After a few minutes, the cluster should be up and running.
If you created a new domain for your cluster, it may take some time until the cluster is formed. If you run journalctl -fu tinc@default to watch the tinc log you should see that the DNS records are not resolvable yet. This should fix itself after a few minutes.
Once tinc is running, etcd should reach it peers. Run journalctl -fu etcd to see the etcd log.
Rolling Upgrades
Another thing most getting started guides are missing is upgrades. Most likely because they are often very environment specific and, well, hard. Which is also why while upgrades should work, this is the most brittle part of it and one of the reason I hesitated to call it “Production Grade”. But heck, if Docker 1.0 was production ready this here is as well.
Since all pod volumes get stored on DO block storage, we consider the systems immutable. To upgrade the cluster, all instances get replaced while Kubernetes makes sure to reschedule services and maintain their availability. The tricky part is to orchestrate this with terraform which does not really support this.
Because of that we need a wrapper script. This script stops etcd on the first old server, which will cause it to remove itself from the cluster. Then it executes terraform and sets -target for each server individually. Unless cluster_state=new is given, the new instance’s provisioning script will block until etcd joined the existing cluster and the cluster is healthy. Only after that, the script continues with the next instance.
Removing an instance from the cluster before replacing it is required. Otherwise the replacement instance can’t join the cluster. This means, if an instance ever dies, you need to manually remove it from the cluster with etcd member remove.
Deployment on Kubernetes
A cluster without services doesn’t make much sense, so I’ll also show quickly how to deploy services to the cluster and make them accessible. I’m using just a bunch of yaml files I can apply with kubectl apply -f: https://github.com/5pi/services
They are pretty specific to my setup, so probably only useful as example. For real reusable components on top of Kubernetes have a look at helm.
Beside the public configuration, you need to require to setup some secrets:
apiVersion: v1
kind: Secret
metadata:
name: default
type: Opaque
data:
pg-password:...
pg-ghost-fish-password: ...
pg-grafana-password: ...
do-token: ...
grafana-gauth-client-secret: ...
smtp-infra-password: ...- For the passwords, just generate something, base64 encode and put them into a file and apply it
- The
do-tokenis a DigitalOcean API token required for floating IP and volume configuration grafana-gauth-client-secretis a Google OAuth client secret for Google Auth based Grafana authenticationsmtp-infra-passwordis the password for a Google Mail I use to send Prometheus alerts
SkyDNS
This is a core service providing DNS resolution for pods. I’m using an adapted copy of the upstream config.
Traffic Tier
I’m using traefik as reverse proxy / load balancer. It depends on a traefik-config ConfigMap where I specific TLS keys etc. It runs three replica and assumes a three node cluster, so we run one instance per host. The vhost configuration is part of the application yaml files.
To have a stable entrypoint into our infrastructure while the host’s IPs change on every rolling upgrade, terraform deployed a floating IP. To assign this IP to any available traefik instance, I’ve created a simple container image and this yaml spec (The IP needs to get changed when using this spec). This will make sure the float IP is always assigned to one of the running hosts.
This requires the do-token.
PostgreSQL
PostgreSQL is used as main database powering this blog for instance. The configuration is straight forward but uses my custom DigitalOcean Storage flexvolume plugin. Before using it the first time, the volume needs to get created, attached, formatted and detached again. You can run the flexvol plugin to do this:
do-volume create pgdata 10G my postgres volume
do-volume attach '{ "volume": "pgdata" }'
mkfs.ext3 /dev/disk/by-id/scsi-0DO_Volume_pgdataAfter that, the yaml file can get applied and postgres should spin up.
Ghost
Next is Ghost, the blogging platform powering this and textkrieg.de. It uses Postgres as database and another DO volume for assets. Since the official Ghost image can’t be easily configured automatically and is huge, I’m using my own (alpine based) Docker image. Although designed as a modern blogging platform, it doesn’t fit particular well into the new container/12factor world. For example, it assumes that the current working directory is writable. Since we want to run ghost as unprivileged user, we need to make the volume writable by that user. Unfortunately there is no good way to do that. People often create images that run chown as root when starting, then dropping privileges. But this can become time consuming and has possible security implications. The upcoming flexvolume redesign will fix this issue. For now we need to make the volume world-writable initially:
do-volume create ghost-fish 1
do-volume attach '{ "volume": "ghost-fish" }'
mkfs.ext4 /dev/disk/by-id/scsi-0DO_Volume_ghost-fish
mount /dev/disk/by-id/scsi-0DO_Volume_ghost-fish /mnt
mkdir -m 777 /mnt/{apps,data,images} # See 5pi/infra#11
umount /mnt
do-volume detach /dev/disk/by-id/scsi-0DO_Volume_ghost-fishHere I choose simplicity over security for the time being since I’m the only operator of this cluster anyway. You might want to make a different trade off.
Now we still need to create databases and users, another thing that hasn’t been addressed by Kubernetes yet. For that we need to find the Postgres pod, then exec into it to create database and users:
kubectl exec -ti postgres-2416409090-jf8uh -- psql -U postgres
create user ghost_fish with password 'pwd-from-secrets.yml';
create database ghost_fish;
grant all privileges on database ghost_fish to ghost_fish;Now we can use the yaml file to deploy Ghost. Beside deploying the pods, we also create a Ingress to configure Traefik. This routes requests for 5pi.de to service ghost-fish on port 80 which is defined above and maps to the Ghost deployment
To access the blog, you still need to create an CNAME DNS record matching the Ingress route and pointing to the managed edge.[DOMAIN] DNS name.
Monitoring
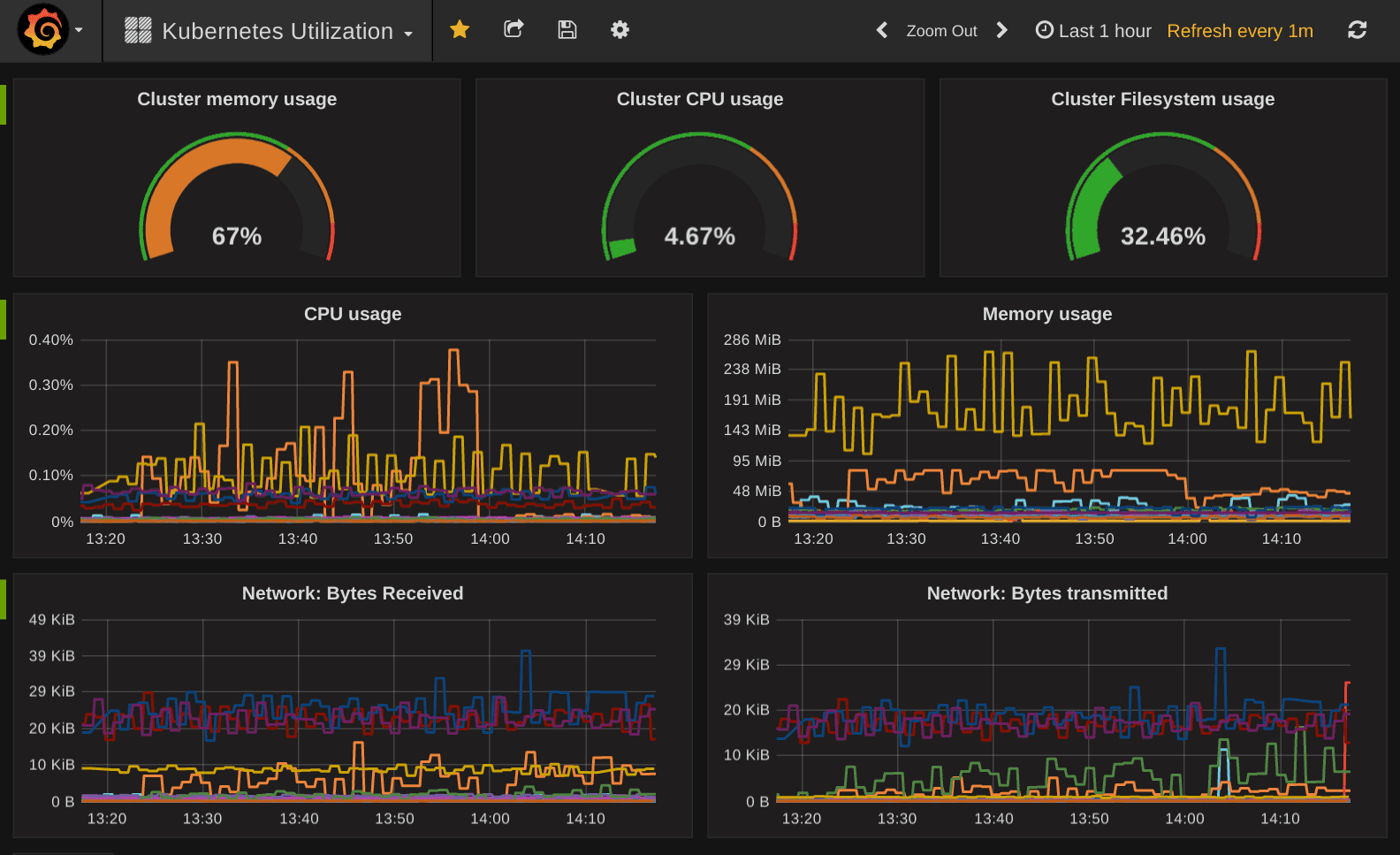
Now that all this is running, it also needs to be monitored properly. Of course I’m using Prometheus for this. The setup is straight forward now that Ingress and Volume configuration is nothing new. It tunes Prometheus to run better on small instances and create a DO Volume to store metrics on. To gather metrics about the services running on Kubernetes, the kube-state-metrics exporter is deployed. To monitor website response times, I also deploy the blackbox-exporter. To send out alerts, two instances of the HA Alertmanager are deployed. This ConfigMap configures Prometheus, sets up alerts and configures the Alertmanager. The SMTP credentials get passed in at container startup. The alerts are quite trigger happy, which is fine in such small cluster. In a bigger cluster you need to adjust those to limit noise. In the end you’re not interested even if whole nodes crash as long as Kubernetes can reschedule the pods. In my tiny cluster I would be surprised if a node crashes, so I alert on this for now.
I’m also using Grafana to show metrics on dashboards. Grafana is configured to use Google OAuth authentication against my Google Apps account. This allows Grafana to be available on the public internet and allow everyone in my Google Apps Org to access it.
Here is where the wildcard DNS domain comes in handy. Instead of having to add new DNS record for each new service like Grafana, we just access it via the wildcard domain: A request to anything.edge.[DOMAIN] ends up at the floating IP and is accepted by a traefik instance. So the only thing we need to configure is the host in the Ingress definition.
Retrospective and Future
I’ve started all this a few month ago already with the goal of building a small cluster from scratch. I didn’t want to use tons of bash scripts not running on a specific cloud. Back then there was kops, which I would recommend to look at first if you’re deploying to AWS.
Now there is also kubeadm which looks like a promising way to setup a cluster and I might change my deployment to use it instead. I’ll also consider using CoreOS and cloud-config to configure the Kubernetes components, as well as looking deeper into systemd units to coordinate stopping of services and draining of hosts.
If you’re looking for reusable components on top of Kubernetes, there is Helm which might be a better option than just keeping the services yaml files around. You might be also interested in CoreOS’s Operator to fully automate Prometheus operations.
The most important next thing on my TODO list is proper tests though. I want a full integration test which spins up a new cluster, deploys services to it, runs blackbox tests, runs an rolling upgrade and tests that during and after that the cluster services are available.
Pull requests to make this more generic and fix issues are welcome, but I won’t accept larger changes until I got the tests going.
Update
Feel free to discuss and comment on Hacker News.
